Neural network acceleration
Why accelerate
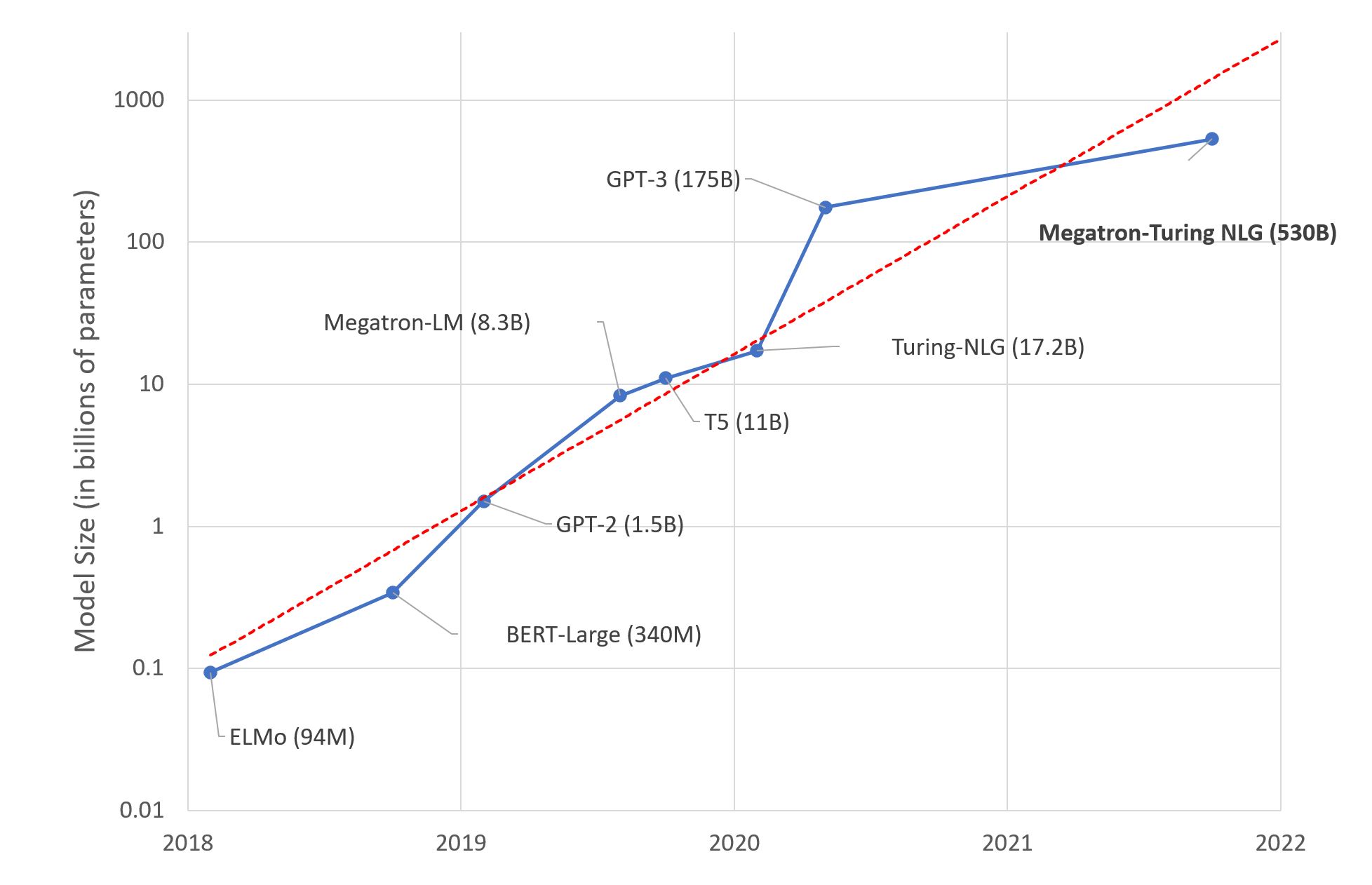
Well, we have neural networks, they are awesome, they work but there’s a problem. THEY ARE HUGE. We scaled from a hundred of millions of parameters to hundred of BILLIONS. This problem makes using neural networks in real life quite hard as you normally don’t have this huge computational capabilities to run them anywhere.
Neural networks have proven to be a very valuable tool in scenarios where the transformation from inputs to outputs is unknown. Suppose you are asked to write an algorithm to classify an image if it’s a cat or a dog, how would you do that ? Well first you might ask yourself, “what makes an image a cat?”. Answering this question is incredibly hard because a vast amount of cases to cover in order to have your algorithm generalizable. This is where neural networks shine; Given an input $ x_{i} $ with its respective label $ y_{i}$ you can use a neural network model with a set of parameters $\theta$ denoted by $ M(\theta) $ to approximate $y_{i} = f(x_{i})$. Normally with enough data you can get a very good estimate of $f$. However, this comes at a huge cost, training and running these large networks is expensive in terms of time and memory because of the huge amount of parameters that you need to learn to get the best approximation, this makes these models hard to use in real life scenarios. Also, the recent trend of models getting bigger and bigger in order to get better performance is making this problem even harder.
There has been a lot of effort in trying to accelerate these models. Let’s talk more about this.
Accelerating Training vs Inference
It’s important to note something. Accelerating neural networks comes in two forms. Accelerating training and/or accelerating inference.
Training
Accelerating training is the process of speeding up the learning of the parameters of the neural network. This is normally more tricky to get right than accelerating inference.
Inference
Accelerating inference is the process of speeding up the running of a neural network. Normally the process is that you take a trained slow model, and then you try to make it run faster while preserving the same performance.
Both techniques are very helpful because they bring us closer to using these model in real life applications, however, it’s more interesting to look at the acceleration of the training of the neural network or the combination of both.
Techniques
There are a lot of techniques to accelerate neural networks. I can only discuss quantization as this is the one I’m most familiar with. I will try to cover the other techniques in future edits.
Some of the techniques are:
- Layer/Weight Pruning.
- Quantization.
- Knowledge Distillation.
- Parameter Sharing.
- Tensor decomposition.
Quantization
Description:
Quantization1 is an very interesting field of model compression it’s personally my favorite and the one I’m most experienced in so I’ll discuss it the most. To undertand quantization we need to understand the concept of numbers on a computer.
What are numbers:
For us number are just a set of symbols that we use to represent a value. We see and treat numbers in the decimal system (base 10) but there are other systems like binary (base 2) or hexadecimal (base 16). For computers numbers are represented in binary (base 2) which has only 1’s and 0’s. There has to be some standardization on how numbers are represented because it might become very messy and we can’t share computations across systems. This is where the IEEE 754 standard comes in. This standard defines how numbers are represented in binary the most common representation is the floating point representation on 32 bits denoted by fp32 or single precision. This representations reserves 32-bits for every number and is composed of 3 parts:
- Sign bit $s$: 1 bit that represents the sign of the number.
- Mantissa $m$: 23 bits that represent the value of the number.
- Exponent $e$: 8 bits that represent the exponent of the number.
The value of the number is calculated roughly as: $(-1)^{sign} \times 2^{e -127} \times (1 + m)$. This is a very simplified explanation of how numbers are represented in computers. Discussion on how operations are done in this representation and the problems with it is out of the scope of this blog post. The important part is what is mentioned above: This representations reserves 32-bits for every number. Reserves 32-bits for every number. 32-bits for every number. 32-bits. In case you still didn’t get it, this means that every number is represented by 32-bits. This is a lot of space for a number. The most important question is: Do we need that ?. To answer this question, we need to understand what need means.
To be continued…
December 25 2022: It’s christmas so i’ll stop here and continue after the holidays.