Update
This is very outdated. For my most updated portfolio, please visit my profile here
Portfolio
Below is the list of projects I worked on. I believe that your work is as good as you can show it, that’s why I try to put each project in a demo-able format. For now I am using streamlit as a tool to demo the models i build.
Language Modeling for multiple languages
Description
I refined a Large Language Model by fine-tuning it on a customized dataset. Also I implemented a seamless pipeline for deployment on the Bittensor networ to achieve the lowest loss. One of the models is trained on the The Mountain dataset with 20B parameters. The training was made possible with the help of DeepSpeed on an 8x A100 GPU machine.
Tech Stack
- GPT-(2.7,6B,20B) from EleutherAI
- Huggingface for finetuning feature
- The Mountain as a dataset
- Bittensor for deployment
Twitter Sentiment Analysis DEMO
Description
This is the simple model where you can analyze the sentiment of a single tweet by writing it in a text box, or you can also analyze a sentiment of hashtag.
The approach I used is utilizing transfer learning to fine-tune an existing Transformer based model ( specifically the distilbert-base-uncased). I fine-tuned the model on the Sentiment140 dataset.
Tech Stack
- Flair for NLP finetuning and data preprocessing.
- Huggingface for using the
pipelinefeature - Tweepy for fetching the tweets from the twitter.
- Streamlit for building the demo app.
Quantized Neural Network for Object Detection
Description
This work was done as part of a project with a self driving car company. The aim was to take a pre-trained model and try to run it as fast as possible and as light as possible to be used for real-time object detection
The model we used is a MobileNetV2 pre-trained model on ImageNet with SSDLite object detector. The model was trained with Fp-32 data format.
We applied several model compression techniques to reduce the size of the model and monitor it’s performance. Some of the techniques we used are:
- Quantization
- Pruning
- Fused Convolution
- Knowledge Distillation
We got interesting results with the model. The model can reliably detect objects in images with same accuracy as the Fp-32 version while going as low as Int-8 data format.
Disclaimer: This work is not entirely my own. I was part of a team that worked on it.
Tech Stack
- PyTorch for building the model.
- Tensorboard for monitoring the model.
- OpenCV for image processing.
Legal case classification
Description
This project was two folds, first we had to build a model that would classify a legal case based on the description entered into several categories. The aim was to provide a tool that will help lawyers to classify the cases faster and easier. Second, we had to extract the entities from the case description that were relevant to the classification.
Here’s a small sketch of how the system should behave.
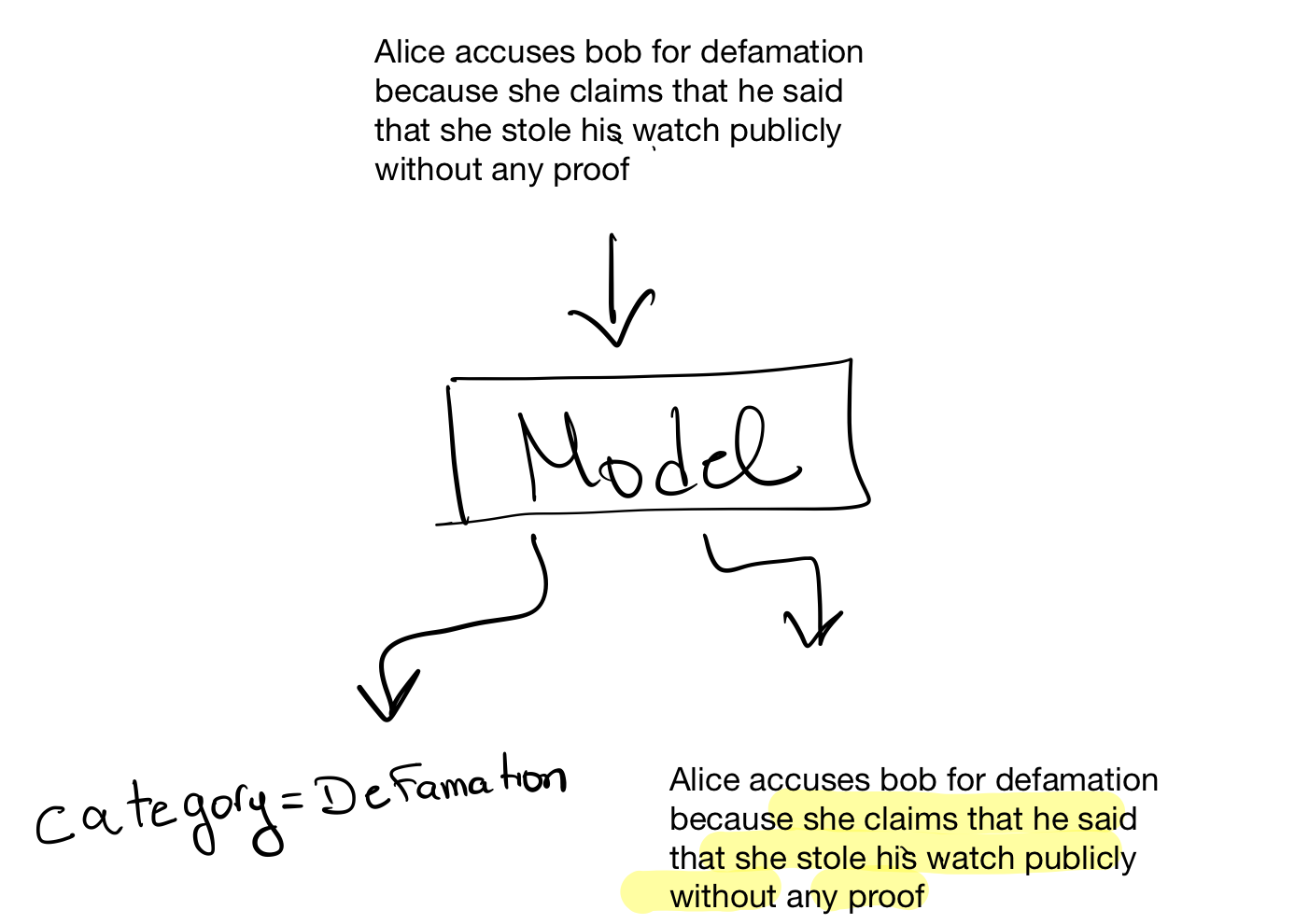
This project was extremely interesting as we faced several technical challenges that I never encountered before. Some of the challenges:
- The data we got was very messy. It was a digitized version of PDF documents
- Each case in our training data was several hundred words long which made it difficult that we used some NLP models.
Tech Stack
- Doc2Vec for building the baseline model.
- PyTorch for building the model.
- Huggingface for using the text tools it provides
- Weights & Biases for monitoring the model training.
- Jupyter Notebooks for showcasing the results of the EDA